🤹♂️ How engineering teams handle unplanned work

This article was originally published on Medium.
Over the past few weeks, a bunch of teams have been asking me the same question — what’s the best way to handle unplanned work?
Plenty has been written about how to prioritise roadmap items, but what about those disruptions or interruptions — the urgent requests from customers, the unscheduled maintenance, the technical questions from customer support, or the accumulating stream of bugs?
Types of interruption
Interruptions are normal, every team experiences them — it’s how they’re handled that matters. Teams shouldn’t feel overwhelmed by them or over-react when they come in. Interruptions can be annoying, but it’s better to view them as opportunities because each interruption is a chance to improve the product in some way.
Interruptions can never be eliminated completely, but we can make them less disruptive and reduce most of the stress associated with them. Here are some of the interruptions that teams will typically experience:
- Critical bugs
These might be addressed as part of on call, but they will often require pulling someone else in to triage or provide support. - Urgent customer requests
These could be feature requests to help close a deal, or simply the need to scope the complexity of delivering an ask for future delivery. - Questions from support
New or less technical support teams are likely to need to rely on engineers for help throughout the day. - Requests from other teams
As teams multiply, dependencies grow with them. Platform teams especially can expect a lot of interruptions in the form of requests from other teams, such as reviewing pull requests or joining their technical planning sessions. - Founder requests
This is also referred to as “seagulling”, when an executive swoops in with an urgent request and everyone reacts.
The suitcase metaphor
People I’ve worked with have likely heard me use a suitcase metaphor to describe an engineering team’s capacity: imagine you’re packing for vacation, and your suitcase is already full of clothes, toiletries, and all the essentials. If you want to add something else, you’ll need to remove something first.
Think of the suitcase as your next cycle’s work. There is only so much you can fit in. You can increase your suitcase’s capacity by hiring more team members, or transferring stuff between other suitcases in other teams.
Where I see teams often fail is that their suitcase is filled to the brim with feature work, leaving no room for the unplanned stuff. That’s when the zips on your suitcase break, and you start spilling toiletries and underpants on the floor.
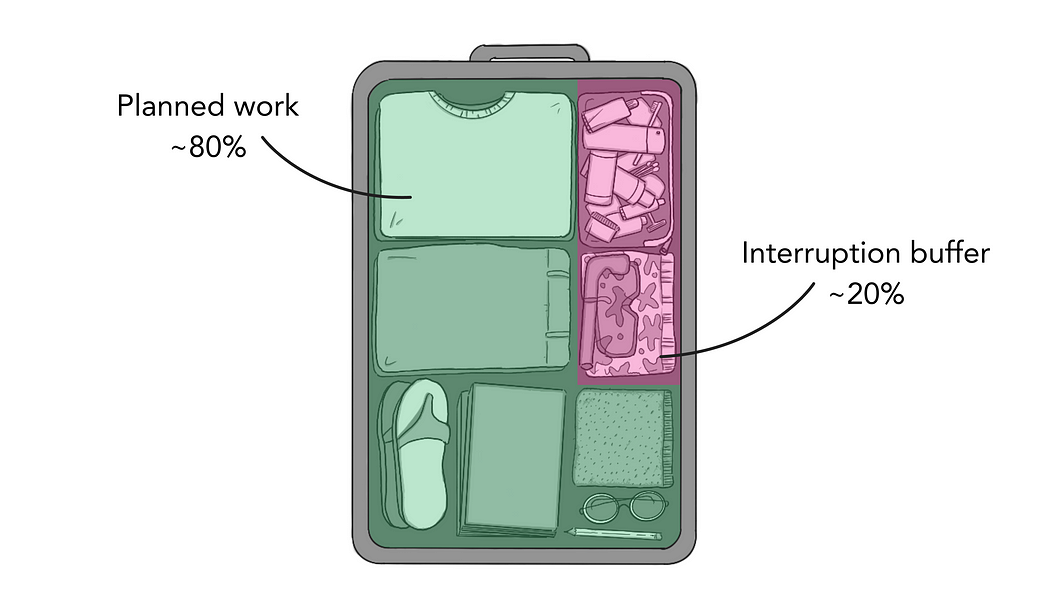
As a rule of thumb for an early stage startup, when packing a sprint’s suitcase, I aim for ~80% planned work with a 20% buffer for interruptions. Obviously this will be different for each company and even each engineering team within it, but if you’re not sure, start with this and adjust over time. 20% might feel like a lot, but you’ll find your planned work becomes much more predictable, and you’ll be able to say “yes” more to the small but impactful requests.
Allocate, measure, adjust
For each sprint or cycle, you’ll want to ensure you’re sticking closely to these allocations. I used a spreadsheet to track planned allocations, and at the end of the week, I looked at how we actually used those to see whether we should adjust these. If I found we had more interruptions than expected, I’d look at why this was (more on that later) and consider increasing the allocation for the next sprint.
Interruption handling methods
Now you’ve got this balance figured out, the next thing you need to decide is how to handle the interruptions when they come in. Someone needs to decide what to work on right away and what to push to later, which is often based on the size, complexity and urgency of the request.
There are a few different approaches to this, and the one that will work best for you will depend on a few things such as how big your engineering team is, the frequency and source of interruptions, and also the maturity of your product’s codebase.
The default approach
Very small teams, such as in a startup’s first year, tend to automatically adopt an ad-hoc approach to interruptions where there is no defined process — they come in, and the team collectively decides whether to tackle them immediately, plan them into a future sprint, or maybe even ignore them and hope the problem goes away.
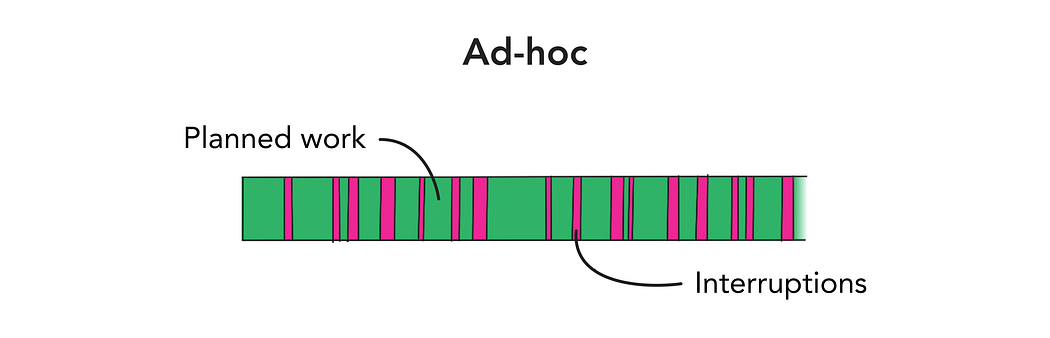
This process works well for small teams who need to be agile. Where this starts to feel painful is when teams grow larger, particularly on the field side, and interrupts become more common. You’ll know this is no longer working when backlogs are building up faster than you can triage each interrupt, or teams are over-reacting to new needs coming in. The impact of this is that engineers end up doing a lot more context switching, and delivery becomes less predictable as the amount of planned work they’re able to complete each sprint takes a back seat to the interrupts.
The interruption sandwich
The decision to dedicate entire sprints to handling interruption work often happens when a team that’s been working ad-hoc reaches a crisis point — maybe their bug or support backlog has gotten so large it would take too long to try and stream alongside a sprint. Doing this is sometimes necessary, but the team shouldn’t be allowed to get into this position too many times. That’s indicative of poor planning or lack of resources.
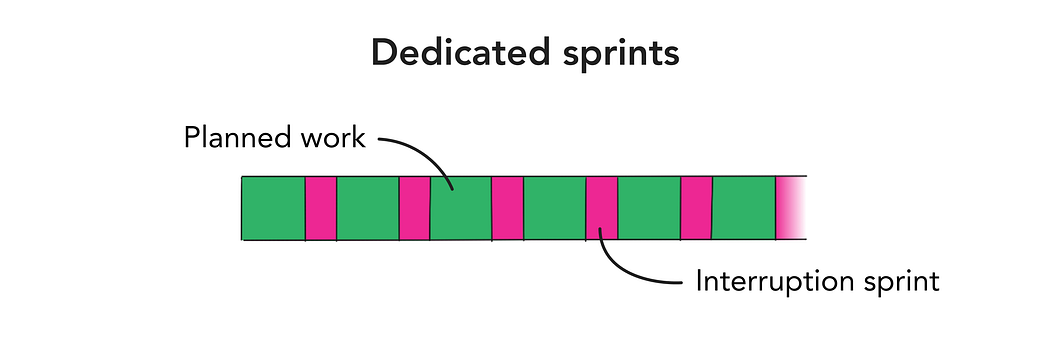
Some teams push bugs to get tackled collectively at regular intervals, such as in a cooldown. I’m not a fan of this approach because bugs can get stale, doing lots of fixes at once can introduce new issues, and it’s also not a great experience as a user to have to wait for bugs to get fixed, even if they’re not critical. It’s like a crash-diet, and makes the quality of the product feel low. There are also some interrupts that simply can’t wait, so sprints rarely looks as neat and tidy as hoped.
The interruption role
The approach that seems to work the best once a team reaches a certain scale is to dedicate an individual to handling the interruptions that come in during a sprint. This responsibility is best rotated, with no planned work assigned to that team member for the duration. If you have an on-call role, it might make sense to tag it onto that, and have the responsibilities cover triaging interruptions during working hours — when there isn’t an ongoing incident of course.
The downside is that this does take an entire team member out of the sprint, but it makes planning more predictable, and helps the rest of the team focus with fewer disruptions and context switches.
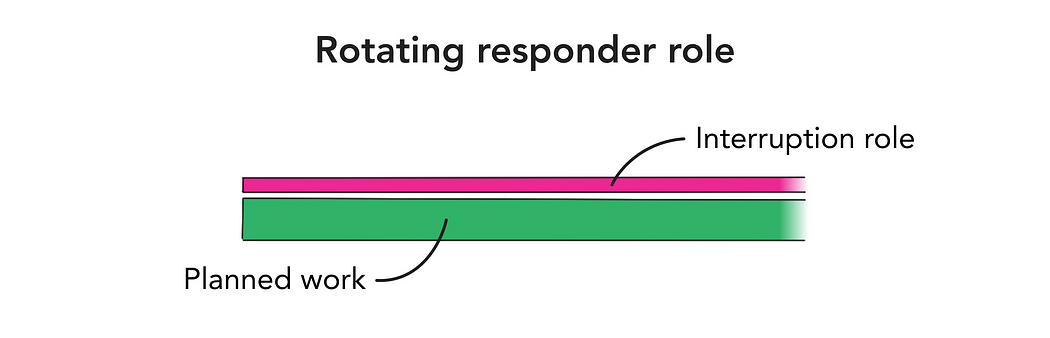
Incident.io wrote about this role on their blog, and how they’ve used this role to their advantage as a way of impressing customers with speedy fixes and improvements. Intercom also have this role. And it’s an approach my team at Snyk settled on after we went through all the above methods as we grew. Almost every other team adopted the same process, rotating the responsibility of triaging bugs, reviewing pull requests, and answering questions in Slack, effectively shielding the rest of the team from as many of the interruptions as possible.
Each interruption is a learning opportunity
If you’re finding yourself having to devote more and more time to interruptions, it’s important to look at what triggered them so you can put steps in place to reduce them. You will never fully eliminate them, but you can make them more manageable. Sprint retros are a great place to discuss this — ask the team about each interruption and whether they feel it was preventable.
Here are some ways to reduce future interruptions:
- Improve your QA process to stop bugs reaching production, such as by running more thorough code reviews, increasing your test coverage, and dogfooding your product internally.
- Ensure you’re scheduling in maintenance so it doesn’t accumulate and bite you in the butt when you’re at your busiest.
- Keep up a regular dialogue with field teams and customers to understand emerging needs, before they become urgent and blocking. Ensure they have opportunities to provide input on the roadmap. Give field teams a way to escalate needs, but prevent them pulling the fire alarm constantly by making them accountable to the need resulting in progress on the account.
- Track verbal and contractual commitments made to customers so that teams aren’t caught out when they are due.
- Be a good communicator to reduce escalations. Customers generally appreciate that bugs happen, or that features they’ve requested can’t be built immediately. What they don’t appreciate is lack of communication, and annoyed customers can put the pressure on teams to respond reactively. Give the customer them regular updates, set a reminder, communicate even when there’s no news, and let them know when to expect the next update. “Just to let you know that the team is still working on this. I’ll give you another update tomorrow”.
- Ensure knowledge is shared so issues can be resolved by more than one person. This includes publishing good documentation so customers and support teams can find answers without having to ask engineering.
- Be aware of seagulling. As a founder, you have a lot of influence in the company. Be aware that when you request a team member to do something, they will likely put aside whatever else they’re doing to respond (even if that’s not your intention). If you’re constantly coming in with requests, the team will thrash, so be aware of your influence and try and follow as much of the existing planning process as possible.
- Learn from each interruption. Products like Jeli help teams understand and learn from incidents, and you can treat certain interruptions as incidents even if they’re not handled by on-call, as the analysis step is helpful in ensuring this isn’t a frequent occurrence.
By handling interruptions better, you’ll not only reduce the frequency and stress associated with them, but I hope it’ll also help you redefine the ones you do have as opportunities to quickly deliver smaller bits of value alongside your planned roadmap.